Pairing with a Partner Who Forgets Everything
How the Sessions Directory Pattern turns documentation into memory
It's Tuesday after the long weekend. I've been context switching between catchup calls and projects all morning. The code is where I left it--but my focus isn't. Most features are delivered, but which one is next? What blockers did I hit? What commands do I need to run?
So I start every session the same way:
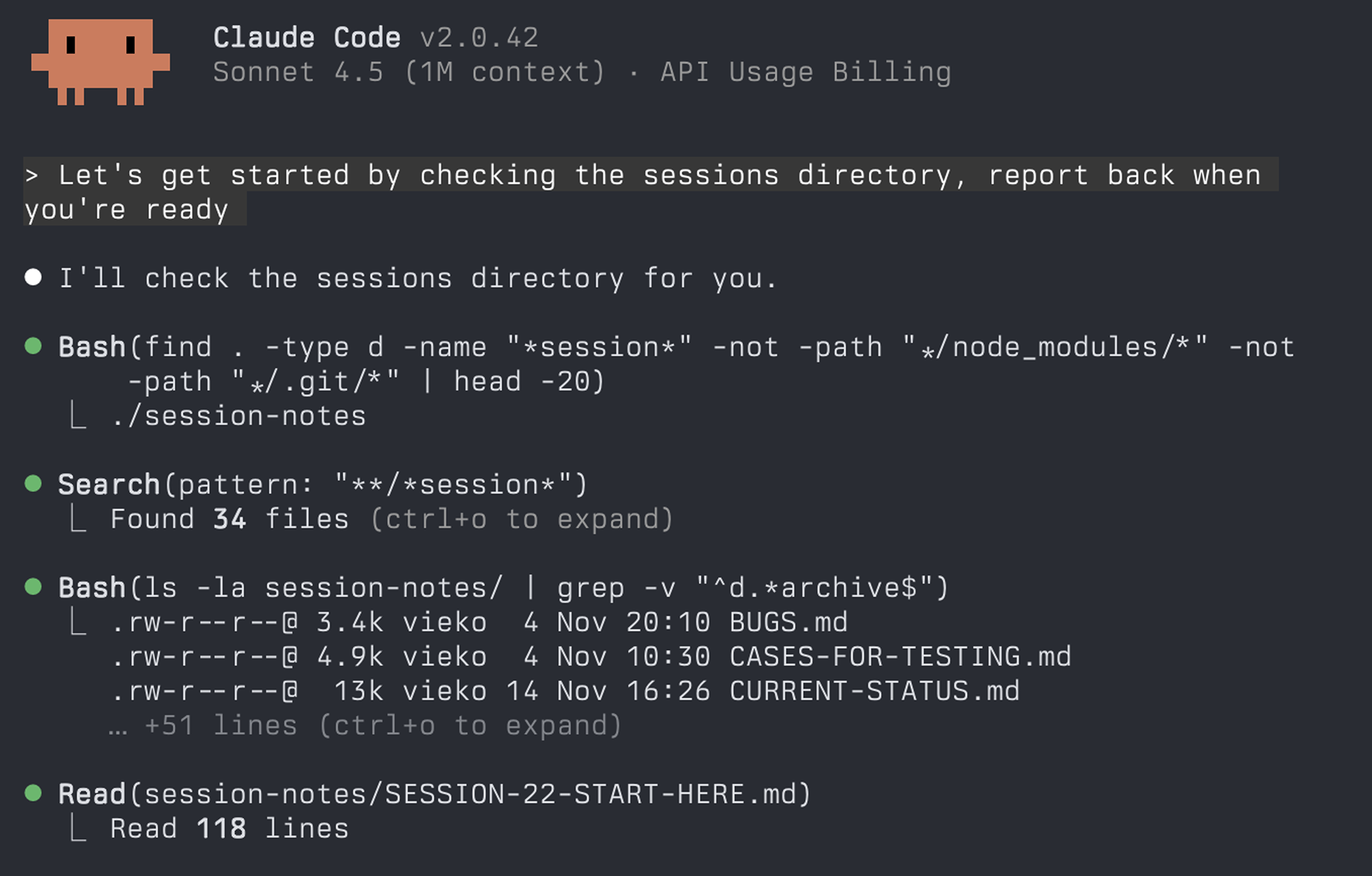
Claude Code, my AI programming partner, reads the project context, figures out where we left off, and reports back:
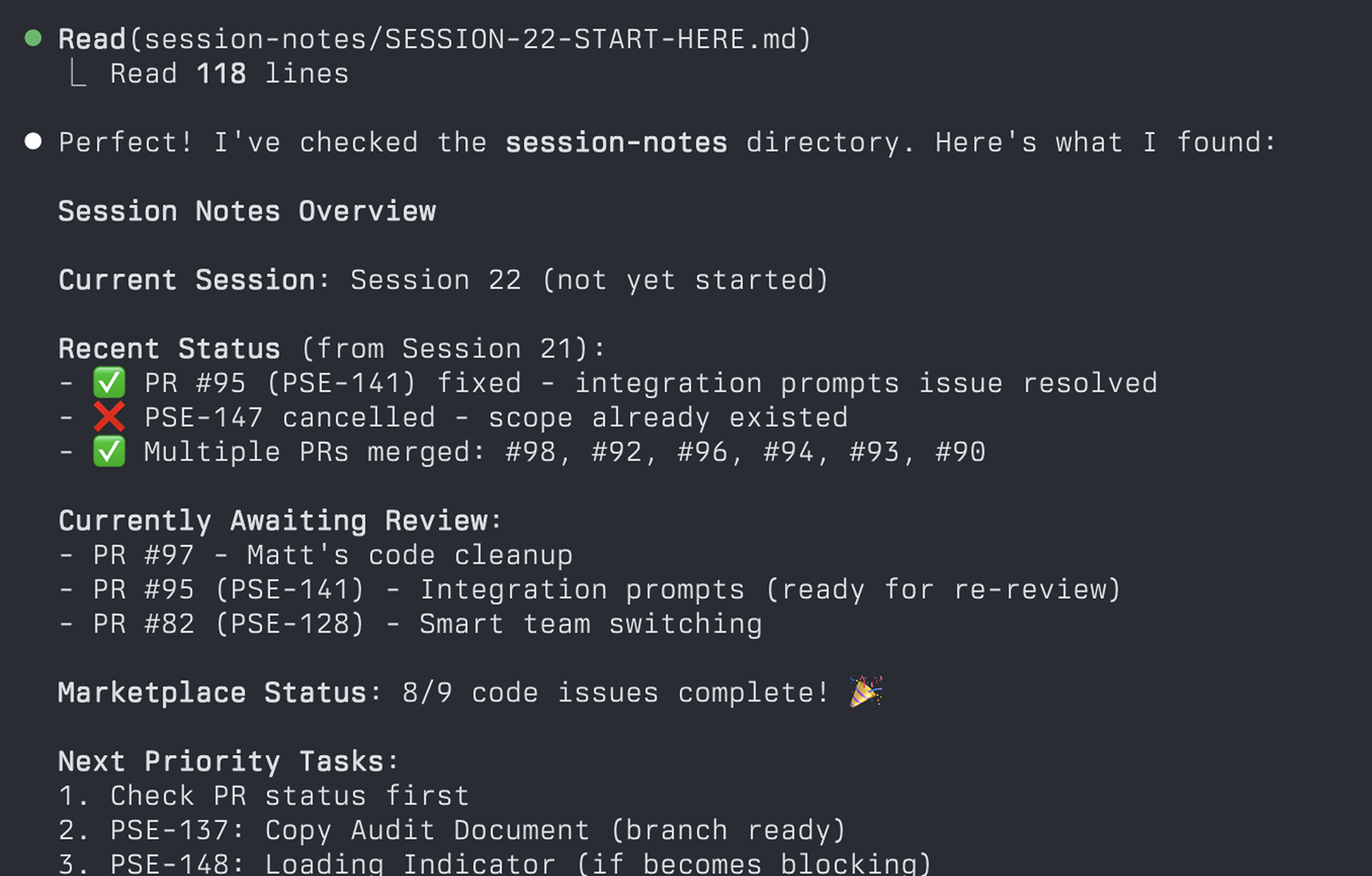
This is the problem I organically solved while pair programming with agents over the last year: how do you work with a partner that has no memory between sessions?
The Context Problem
Humans remember (most of the time). We carry yesterday's mental state into today.
LLMs don't. They're stateless by design[1] --every session starts from zero. You can paste code and explain the architecture, but that takes time. And you forget things. I'd forget to mention the persistent type generation bug we have no control over. Or that switching between laptop and desktop requires a session checkpoint first. Or that we unified Table A + Table B.
Agents will waste time on known issues or break patterns we established weeks ago if we let them. Especially if their context window is reaching a limit.
I needed a saved game for development--a way to pick up exactly where I left off.
Why Not Use Built-In Agent Memory?
Some models now offer persistent memory. Claude Code itself uses file-based memory[2] --CLAUDE.md for "common bash commands and code style guidelines." It's useful for project configuration and preferences.
But that's not the same as session state. Memory features can't track where you left off in a complex migration, what you tried yesterday that didn't work, or which collection to tackle next. They can't organize information by priority or create clean handoffs.
I tried using CLAUDE.md for everything initially --project config, known issues, and session state all mixed together. It worked for a while. Then it grew to 38,000 characters on one project and became too large to be useful. Loading that much context every session was slow and unfocused.
The Sessions Directory
The solution was separation of concerns: CLAUDE.md for project config that rarely changes, and a .sessions/ directory for workflow state that updates constantly.
The structure starts simple: a living index.md file and an archive/ folder. As your project grows, use /document <topic> to create topic-specific documentation--your partner will create a docs/ folder and structure the content for you.
Here's what your session context file might look like:
# Session Context: My Project **Date**: November 18, 2025 **Status**: Building dashboard filters --- ## Current State Working on feature/dashboard-filters branch - Filter UI components in progress - API logic next ## Recent Sessions ### November 16, 2025 **Accomplished**: - Auth refactor merged (PR #127) - Database schema updated **Next**: - Implement filter UI (search, date, tags) - Add API logic for filter parameters ## Next Session Priorities 1. Complete filter UI components 2. Wire up API endpoints 3. Test with large datasets ## Blockers - Need staging API keys for OAuth testing
This keeps active context accessible without drowning your partner in history--which only works if you have a consistent workflow to update it.
Sessions Directory Pattern
A lightweight structure of markdown files that stores the project's current state, decisions, next steps, and histories so your stateless partner can resume work instantly--like loading a saved game.
The Session Loop
Here's how a typical session unfolds:
- 1. Session start--conversational kick-off, not a command
- 2. Agent digests context--last session summary, next actions, proposed todo list
- 3. Priority alignment--we check notes, GitHub issues, Linear comments
- 4. Work--prompt, implement, review, iterate
- 5. Test--agent-guided manual tests, build custom CLIs, or implement tests proper
- 6. Commit & PR--agent commits, I adjust message, create PR
- 7. Session end--agent writes breadcrumbs for next time
This aligns with Claude Code's agent loop[3] --but extends it across sessions, days, and weeks.
This is not prompting. It's a workflow.
Explicit Handoffs
At the end of every session, I trigger the handoff: "This is a good stopping point, let's update the sessions directory and we'll continue in a new session." Or just use /end-session. Your partner handles the protocol:
- Commit changes with descriptive messages
- Update
index.mdwith what was accomplished - Note blockers or pending decisions
- Set next session priorities
Your partner does the work--you just trigger it. And whenever you come back, it's all right there, ready to be surfaced and continued.
Eliminating Context Debt
Here's the twist: writing session notes made development faster.
Most warnings about "context rot" are really warnings about unstructured context--giant dumps of notes, logs, and code that blur together and confuse the model[4]. That's valid.
But when session notes are structured--indexed, scoped, and predictable--the effect flips.
Patterns become reusable. Known issues don't resurface. Your partner drifts and attempts to reinvent much less; it follows the documented path. Once that pattern lived in the sessions directory, every feature took a fraction of the time to implement with little rework.
Start Small
You don't write session notes manually. At session start and session end, your AI programming partner generates them using patterns that make sense to it--or templates you provide.
Start simple: a single file. As it grows, evolve it into a directory. Start with the essentials, add session files and topic docs as needed. Have your partner archive sessions when the feature ships or the branch merges. Markdown files work remarkably well.
My colleague Aman suggested turning this pattern into a tool, so I built one.
Try it now
Run this in any project to scaffold a Sessions Directory with templates and slash commands:
npx create-sessions-dir
The pattern works. The tool helps you start.
Now go make some memories 💪🏼
This post was written using the pattern it describes, with Claude Code as my pair writing partner.
[1] Letta articulates the core problem well: LLMs are stateless by design, so we need memory systems. Their solution uses code infrastructure; mine uses markdown files.
[2] Claude Code's memory management documentation recommends creating CLAUDE.md files for project preferences, coding style, and frequently used commands. This file-based approach aligns with the Sessions Directory Pattern--CLAUDE.md handles project config, while sessions/ handles workflow state.
[3] Claude Code's best practices guide emphasizes iterative workflows--write code, run tests, adjust, and repeat. The Sessions Directory Pattern works at a different level by providing the persistent state that makes these iterations work across days and weeks, not just within a single session.
[4] Box CEO Aaron Levie's comments on context rot get at a real problem: feeding an AI model too much context can degrade output quality--"the model will just get very confused." Structured documentation helps by curating what matters.